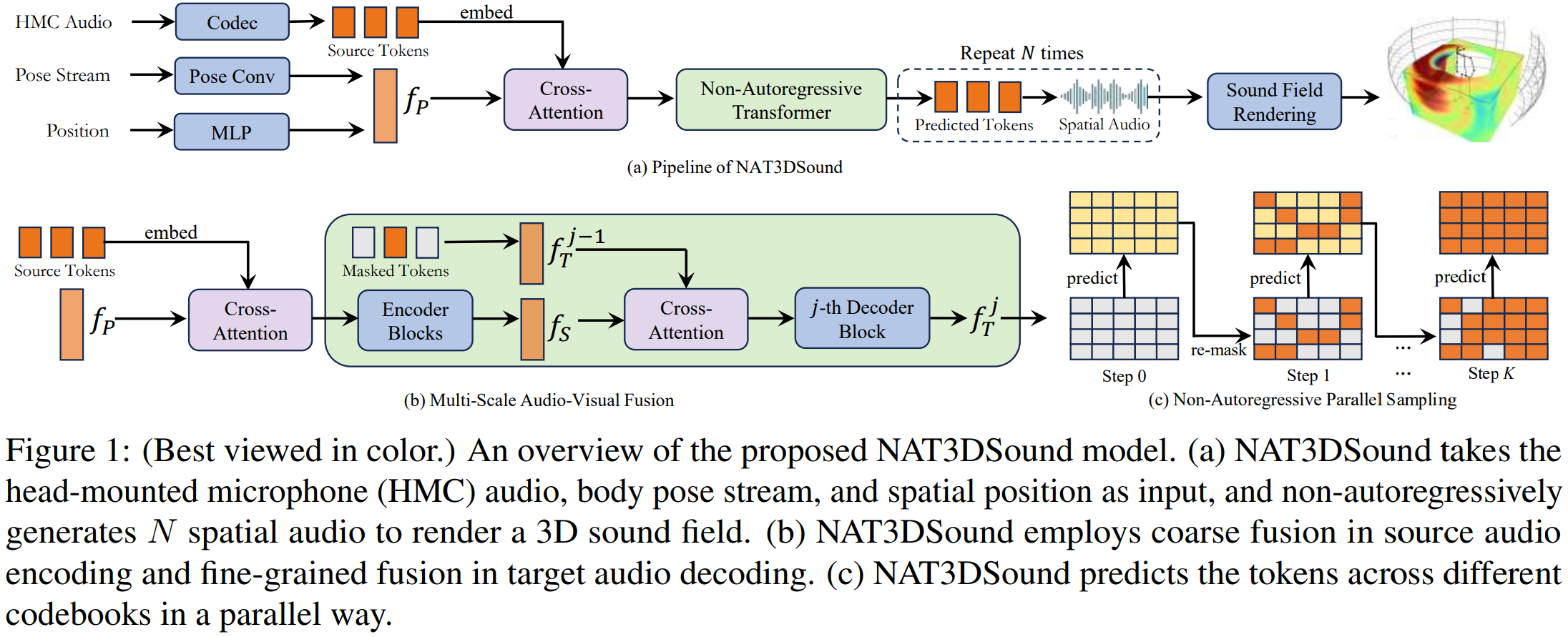
Abstract: 3D spatial sound field synthesis takes the head-mounted audio signals and body poses as input and renders a 3D sound field around the center body, in which spatial audio can be inferred at any arbitrary position. To achieve this, a multi-modal system is required to spatialize input audio signals with the guidance of pose streams. Then, a numerical method is used to render the sound field with hundreds of spatial audio. However, there exist several challenges including hybrid audio input signals, cross-modal matching, and few data resources. To address them, we propose NAT3DSound, a unit-based framework for high-quality 3D spatial sound synthesis, which consists of 1) a general tokenization scheme for both dense and impulsive input audio signals, 2) a non-autoregressive transformer with multi-scale modality fusion for efficient cross-modal alignment and 3) a parallel sampling strategy for fast prediction. Furthermore, we investigate the feasibility of acoustic pre-training for low-resource learning in data-scarce scenarios. Extensive experiments and ablation studies demonstrate the effectiveness of NAT3DSound in terms of spatialization quality and generalization ability. Audio samples are available at http://NAT3DSound.github.io/
| Recording | SoundingBodies | MagNet | Visual-MagNet | NAT3DSound | ||
|---|---|---|---|---|---|---|
| Sample 1: | ||||||
| Audio Visualization: |
|
|
|
|
|
|
| Description: | The participant #1 performed fist bump with heavy clothing that produces more noise (jackets, coats, ...). | |||||
| Sample 2 clip1: | ||||||
| Audio Visualization: |
|
|
|
|
|
|
| Description: | (0s-8s)The conversational speech from participant #3 that sitting with light clothing (T-Shirt, light sweater, ...). | |||||
| Sample 2 clip2: | ||||||
| Audio Visualization: |
|
|
|
|
|
|
| Description: | (8s-16s)The conversational speech from participant #3 that sitting with light clothing (T-Shirt, light sweater, ...). | |||||
| Sample 2 clip3: | ||||||
| Audio Visualization: |
|
|
|
|
|
|
| Description: | (16s-24s)The conversational speech from participant #3 that sitting with light clothing (T-Shirt, light sweater, ...). | |||||
| Sample 2 clip4: | ||||||
| Audio Visualization: |
|
|
|
|
|
|
| Description: | (24s-32s)The conversational speech from participant #3 that sitting with light clothing (T-Shirt, light sweater, ...). | |||||
| Sample 2 clip5: | ||||||
| Audio Visualization: |
|
|
|
|
|
|
| Description: | (32s-40s)The conversational speech from participant #3 that sitting with light clothing (T-Shirt, light sweater, ...). | |||||
| Sample 3: | ||||||
| Audio Visualization: |
|
|
|
|
|
|
| Description: | The participant #5 sat and punched other hand at a time with light clothing. | |||||
| Recording | SoundingBodies | MagNet | Visual-MagNet | NAT3DSound | ||
|---|---|---|---|---|---|---|
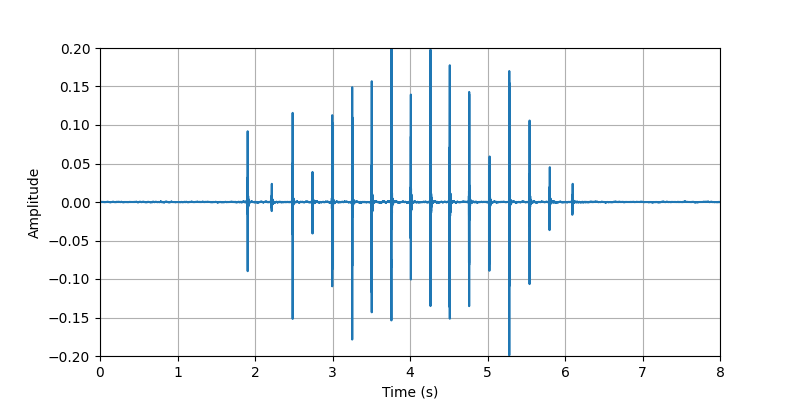
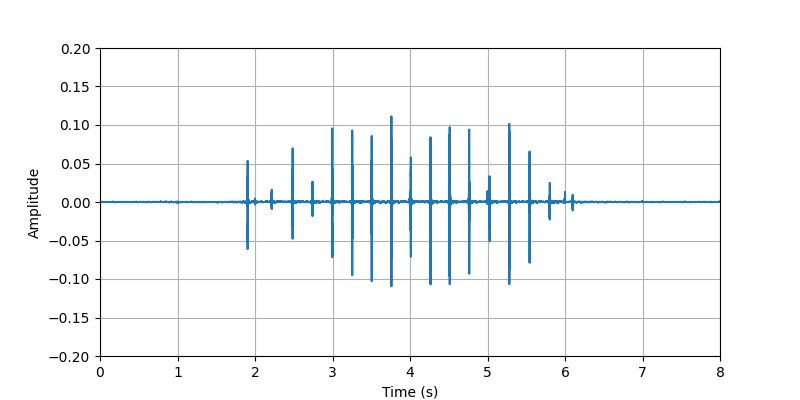
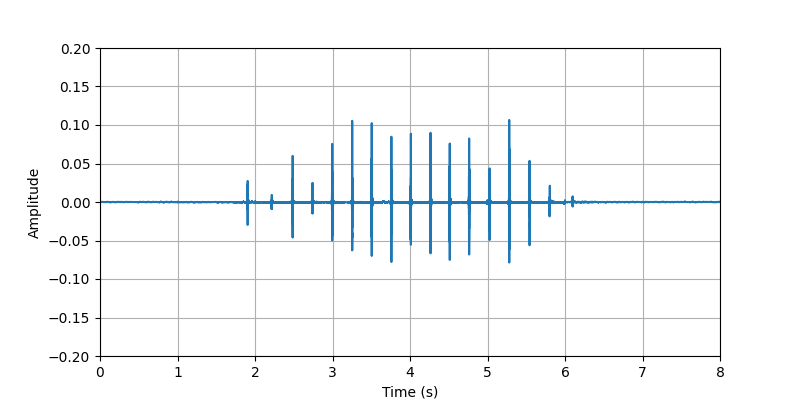
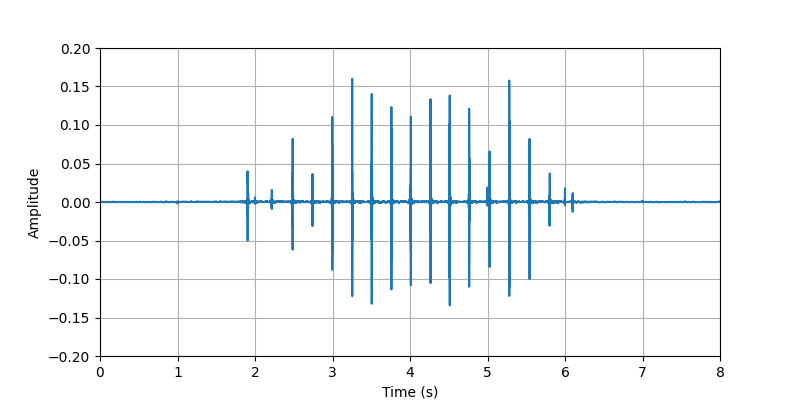
| Sample 1: | ||||||
| Audio Visualization: |
|
|
|
|
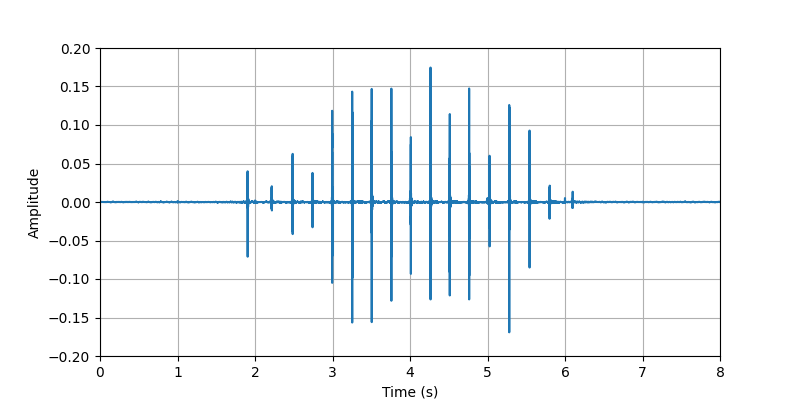
|
|
| Description: | The participant #2 performed tapping whole body (searching for phone, keys, wallet, ...) with light clothing. | |||||
| Sample 2 clip1: | ||||||
| Audio Visualization: |
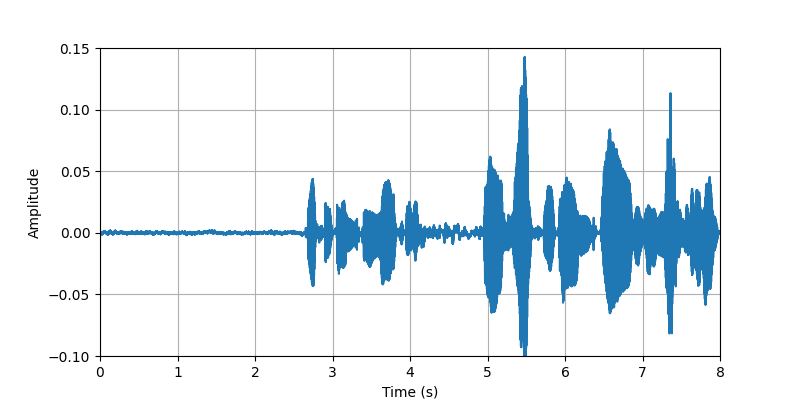
|
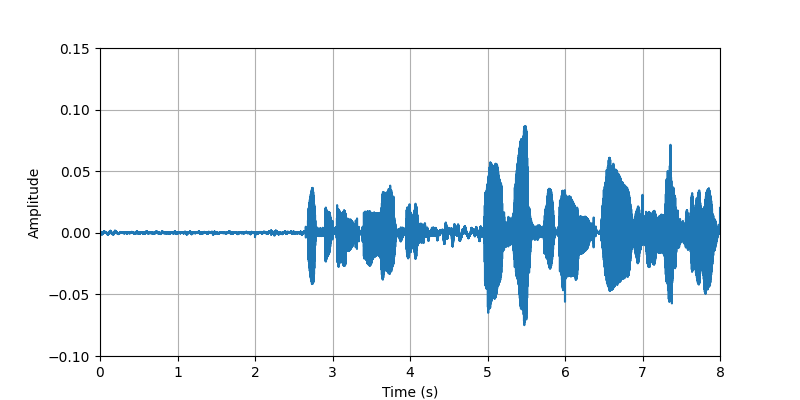
|
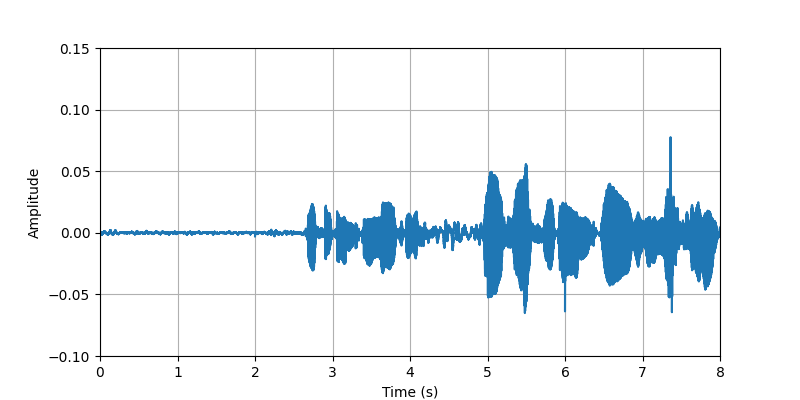
|
|
|
|
| Description: | (0s-8s)The conversational speech along with body sounds and gestures from participant #2 that standing with heavy clothing. | |||||
| Sample 2 clip2: | ||||||
| Audio Visualization: |
|
|
|
|
|
|
| Description: | (8s-16s)The conversational speech along with body sounds and gestures from participant #2 that standing with heavy clothing. | |||||
| Sample 2 clip3: | ||||||
| Audio Visulization: |
|
|
|
|
|
|
| Description: | (16s-24s)The conversational speech along with body sounds and gestures from participant #2 that standing with heavy clothing. | |||||
| Sample 2 clip4: | ||||||
| Audio Visualization: |
|
|
|
|
|
|
| Description: | (24s-32s)The conversational speech along with body sounds and gestures from participant #2 that standing with heavy clothing. | |||||
| Sample 2 clip5: | ||||||
| Audio Visualization: |
|
|
|
|
|
|
| Description: | (32s-40s)The conversational speech along with body sounds and gestures from participant #2 that standing with heavy clothing. | |||||
| Sample 3: | ||||||
| Audio Visualization: |
|
|
|
|
|
|
| Description: | The participant #2 performed applause(i.e. clap hands in front of body) with heavy clothing. | |||||
| Recording | Finetune-1person | Finetune-2person | Full | |
|---|---|---|---|---|
| Sample 1: | ||||
| Audio Visualization: |
|
|
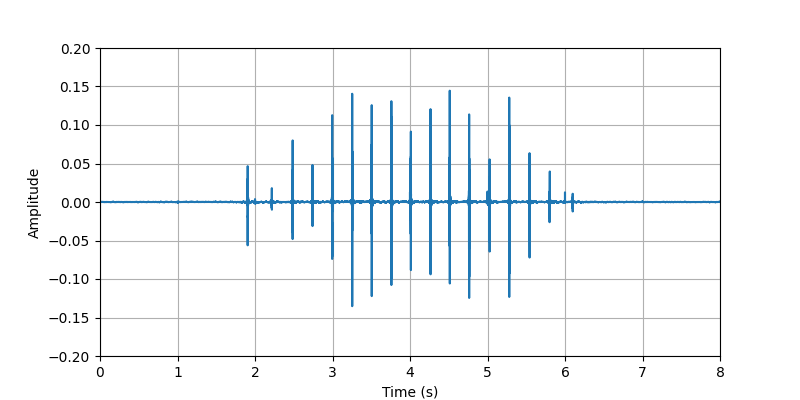
|
|
| Description: | The participant #2 performed tapping whole body (searching for phone, keys, wallet, ...) with light clothing. | |||
| Sample 2 clip1: | ||||
| Audio Visualization: |
|
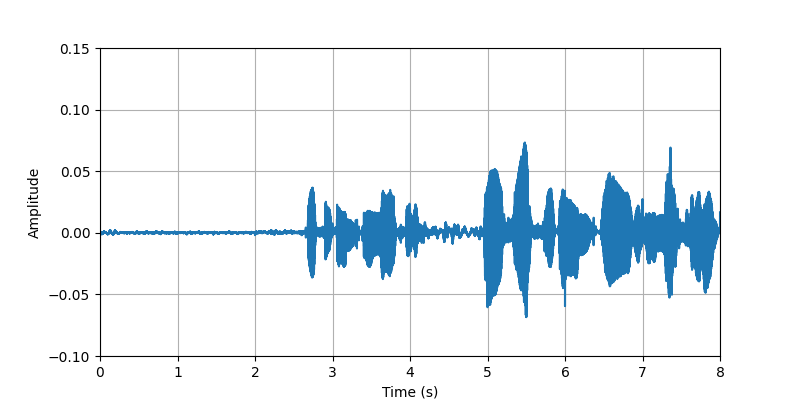
|
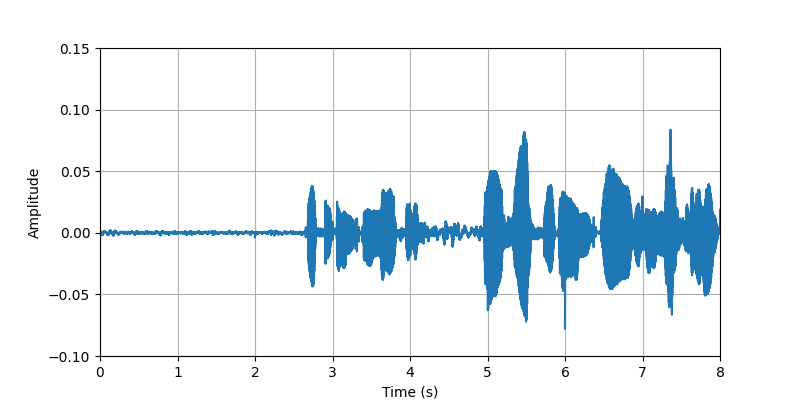
|
|
| Description: | (0s-8s)The conversational speech along with body sounds and gestures from participant #2 that standing with heavy clothing. | |||
| Sample 2 clip 2: | ||||
| Audio Visualization: |
|
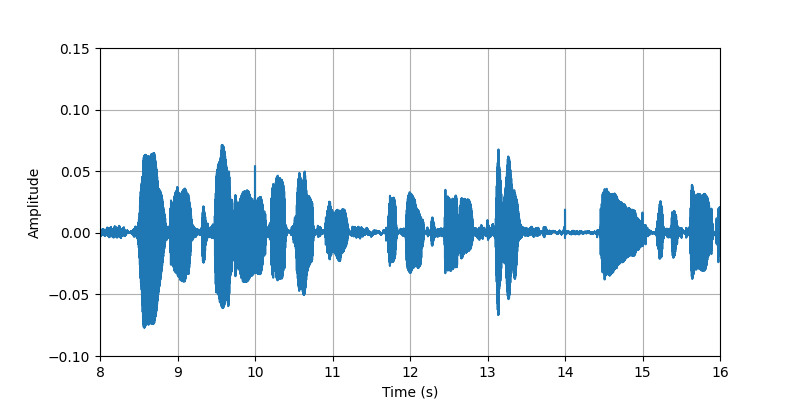
|
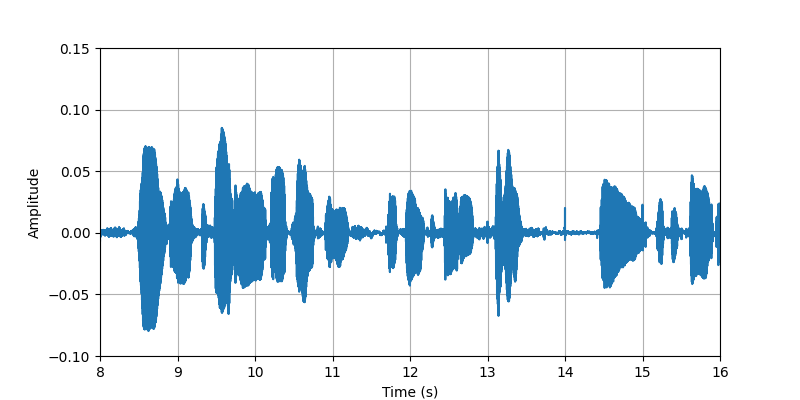
|
|
| Description: | (8s-16s)The conversational speech along with body sounds and gestures from participant #2 that standing with heavy clothing. | |||
| Sample 2 clip3: | ||||
| Audio Visualization: |
|
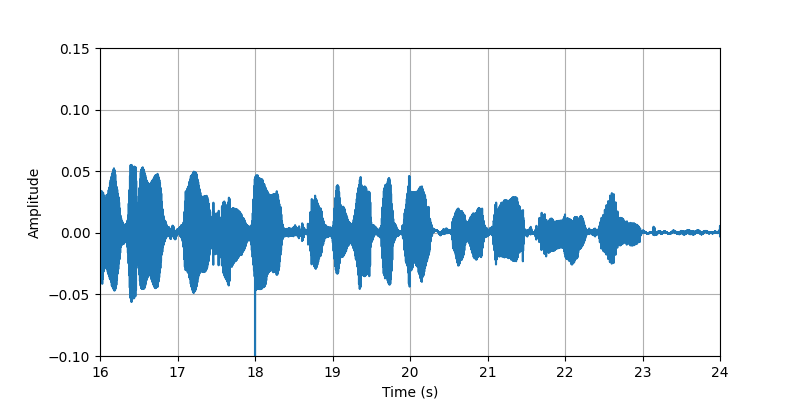
|
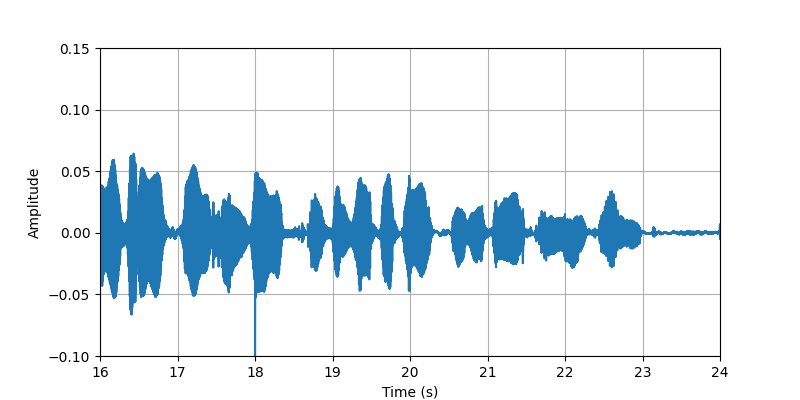
|
|
| Description: | (16s-24s)The conversational speech along with body sounds and gestures from participant #2 that standing with heavy clothing. | |||
| Sample 2 clip4: | ||||
| Audio Visualization: |
|
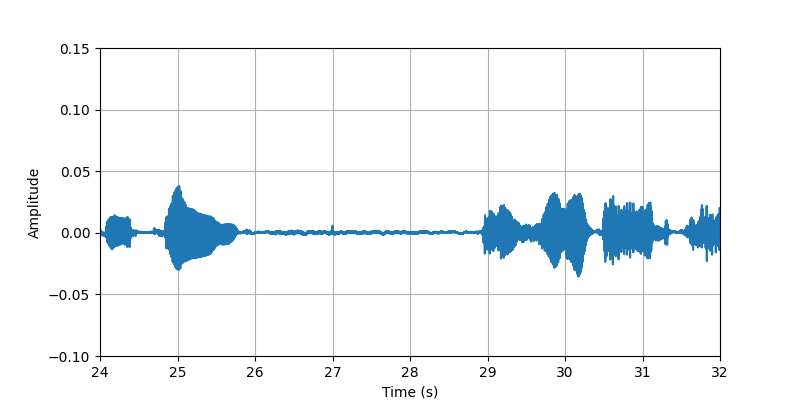
|
|
|
| Description: | (24s-32s)The conversational speech along with body sounds and gestures from participant #2 that standing with heavy clothing. | |||
| Sample 2 clip5: | ||||
| Audio Visualization: |
|
|
|
|
| Description: | (32s-40s)The conversational speech along with body sounds and gestures from participant #2 that standing with heavy clothing. | |||
| Sample 3 | ||||
| Audio Visualization: |
|
|
|
|
| Description: | The participant #2 stood and clapped with heavy clothing to cover as many spatial positions as possible. | |||